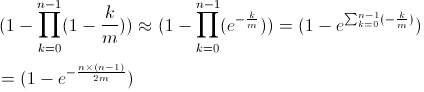前言
这个博客是用基于Python的Kukkaisvoima搭建的,前几天才发现Kukkaisvoima已经更新到14了。从官网下载源码后,我大致看了一下,主要是一些小修改:添加了年和月的目录、修改了时间格式,终于添加了渴望已久的RSS图标;)。
既然更新了博客程序就不得不说写博客了,由于Kukkaisvoima只支持纯HTML的txt文本方式(连文件后缀都要.txt),所以写起来很费劲。话说HTML尽管很直观但也不是容易写的。之前遇到的最大困难是不支持自动换行,我的做法是直接改Kukkaisvoima源码,在每一行最后加<p>分段,凑合着还能用。最近发现很多人都用Markdown写博客,Markdown语法简洁,可以很方便转成HTML,最主要的是有Python支持,看起来很符合我的胃口,所以马上动手把Markdown集成进Kukkaisvoima。
准备
- Markdown的语法说明
- Python Markdown库最新版本为2.1.1
Linux下安装:
wget http://pypi.python.org/packages/source/M/Markdown/Markdown-2.x.x.tar.gz
tar xvzf Markdown-2.x.x.tar.gz
cd Markdown-2.x.x/
sudo python setup.py install
命令行用法:
markdown_py --help
- Vim的Markdown语法插件,Markdown文件扩展名为.md/.mkd/.mkdn/.mark*
由于Kukkaisvoima只支持后缀.txt文件,所以使用语法文件时可以手动修改文件类型时Vim支持Markdown语法,注意txt文件编码是UTF-8,在Vim命令模式输入:
:set filetype=markdown
在Vim配置文件中加入下面几行可以实时转换并用浏览器查看效果,按md进行转换:
" markdown to HTML on Linux
nmap <leader>md :w<cr>:silent !markdown_py "%">"%.html"<cr>:silent !firefox "%.html"<cr>
" Markdown to HTML on Windows
nmap <leader>md :w<cr>:silent !markdown.py "%">"%.html"<cr>:silent !"%.html"<cr>
修改
在Kukkaisvoima的主文件index.cgi开头添加Markdown的Python库导入:
import markdown
在index.cgi的Entry类析构函数中读取博客文本时进行Markdown解析:
class Entry:
firstpre = re.compile("<p.*?(</p>|<p>)", re.DOTALL | re.IGNORECASE)
whitespacere = re.compile("s")
def __init__(self, fileName, datadir):
self.fileName = fileName
self.fullPath = os.path.join(datadir, fileName)
# Markdown support
tempf = open(self.fullPath, 'r')
self.headline = tempf.readline()
temptext = tempf.read()
temptext = temptext.decode(encoding)
temptext = markdown.markdown(temptext)
temptext = temptext.encode(encoding)
self.text = temptext.splitlines(True)
#self.text = [line for line in self.text if not line.startswith('#')]
#self.headline = self.text[0]
#self.text = self.text[1:]
self.author = defaultauthor
self.cat = ''
name, date, categories = fileName[:-4].split('_')
self.cat = categories.split(',')
self.date = generateDate(self.fullPath)
self.comments = getComments(self.fileName)
self.url = "%s/%s" % (baseurl,
quote_plus(self.fileName[:-4]))
由于Markdown的Python库只支持Unicode的输入输出,所以需要在UTF-8和Unicode之间进行转换。
效果
大功告成之后测试一下,用Markdown修改之前写的博文:
Markdown:
**引言:**
>A Wise old computer scienist once said: Make your data structure
>smart and your code dump.
>
>We need SMART Models, THIN Controllers, and DUMB Views.
HTML:
引言:
A Wise old computer scienist once said: Make your data structure
smart and your code dump.
We need SMART Models, THIN Controllers, and DUMB Views.
总体来说效果不错,基本上能满足我写博客的需求了,至于其他的如添加Tag的属性之类的只能用HTML来写了:)。