这个全文RSS程序我已经断断续续写了差不多一个月了,期间为了其他事而耽搁了一下。一开始写这个程序主要是我一直不习惯Google Reader中某些不输出全文的RSS,非得你再点一下鼠标不可,我等懒人怎能容忍。
一开始上网搜索全文RSS程序,只搜索到阮先生的这篇,大致看了这个PHP写的FiveFilter还算简单,决定用Python在服务器上实现一个。
期间慢慢看了一些RSS标准、Python RSS库之类的东西,大致框架如下:
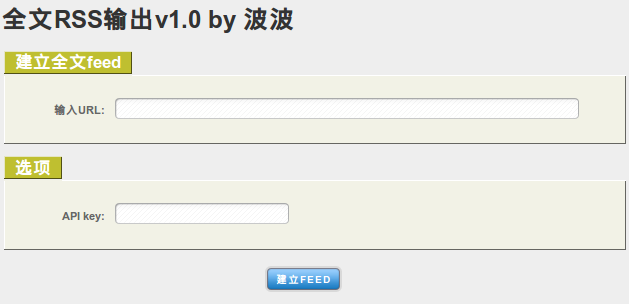
- 前端照搬FiveFilter的Web界面。
- 后端用Python实现,包括RSS读取、内容全文解析、RSS保存等等。
一开始因为RSS中的每个网页都要用urllib去读一遍再解析一遍比较耗时,所以打算在后台搞个daemon进行更新。后来改进了方案,直接用Python的多线程进行读取和解析,解决了时间问题。Python的线程库threading是个神器,搞数据挖掘的用这个应该很方便:)。
接下来参考FiveFilter的PHP代码和这篇神作feedcache搞定各种Python库:
- feedparser 5.1.2:RSS解析就靠它了,这个库用的人很多,不过感觉解析速度很慢:)。
- Readability-lxml 0.2.5 这个库就大名鼎鼎了,主要用来扣取网页中的正文部分,还有专门的网站提供各种浏览器的工具。
最后我自己写了个RSS输出类搞定一切。
其他的细节太多了,比如如何确定RSS要保持多少时间才去更新。我大致看了一下Google Reader的抓包数据,发现Google Reader大致一小时抓一次,所以我把RSS的更新时间也设置成一小时。
[23/May/2012:19:34:46 +0800] "GET /index.cgi/feed/ HTTP/1.1" 200 6272 "-" "Feedfetcher-Google; (+http://www.google.com/feedfetcher.html;
[23/May/2012:20:44:46 +0800] "GET /index.cgi/feed/ HTTP/1.1" 200 6272 "-" "Feedfetcher-Google; (+http://www.google.com/feedfetcher.html;
[23/May/2012:21:39:26 +0800] "GET /index.cgi/feed/ HTTP/1.1" 200 6272 "-" "Feedfetcher-Google; (+http://www.google.com/feedfetcher.html;
[23/May/2012:22:46:56 +0800] "GET /index.cgi/feed/ HTTP/1.1" 200 6272 "-" "Feedfetcher-Google; (+http://www.google.com/feedfetcher.html;
还有为了提高效率,每次读RSS源都用HTTP的条件判断(ETage and Last-Modified), 减少读取次数等等。
最后晒一下成果,项目源码在这里。我在服务器上搭建的网站程序在这里(已经移除),最后发张效果图。